



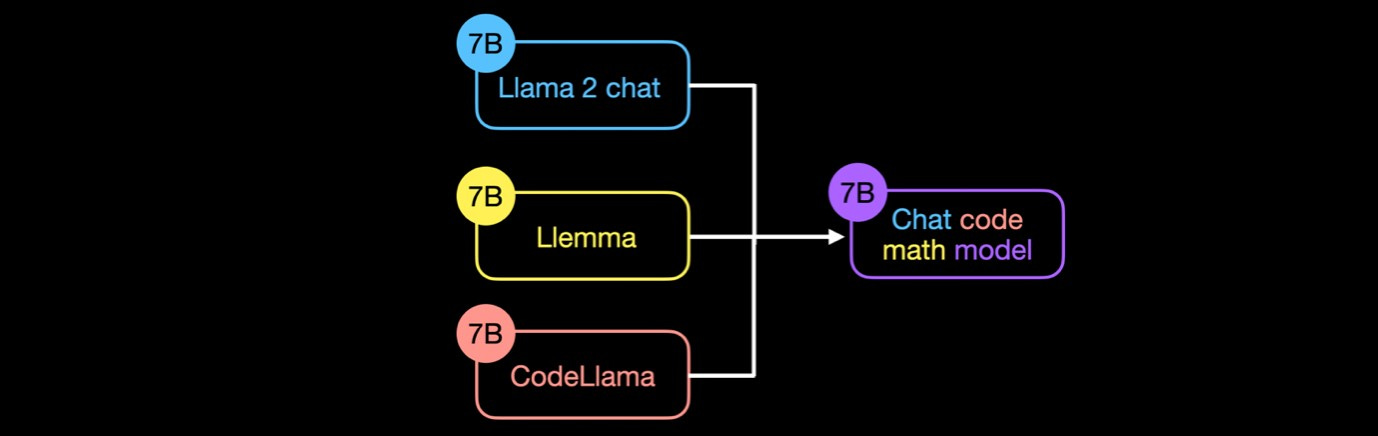
Model merging refers to combining multiple distinct Large Language Models (LLMs) into a single unified LLM without requiring additional training or fine-tuning. The primary rationale behind this approach is that different LLMs, each optimized to excel at specific tasks, can be merged to enhance performance across the combined expertise of both models.
Mergekit
MergeKit, a tools for merging pretrained LLM and create Mixture of Experts (MoE) from open-source models
Merge Methods
A quick overview of the currently supported merge methods:
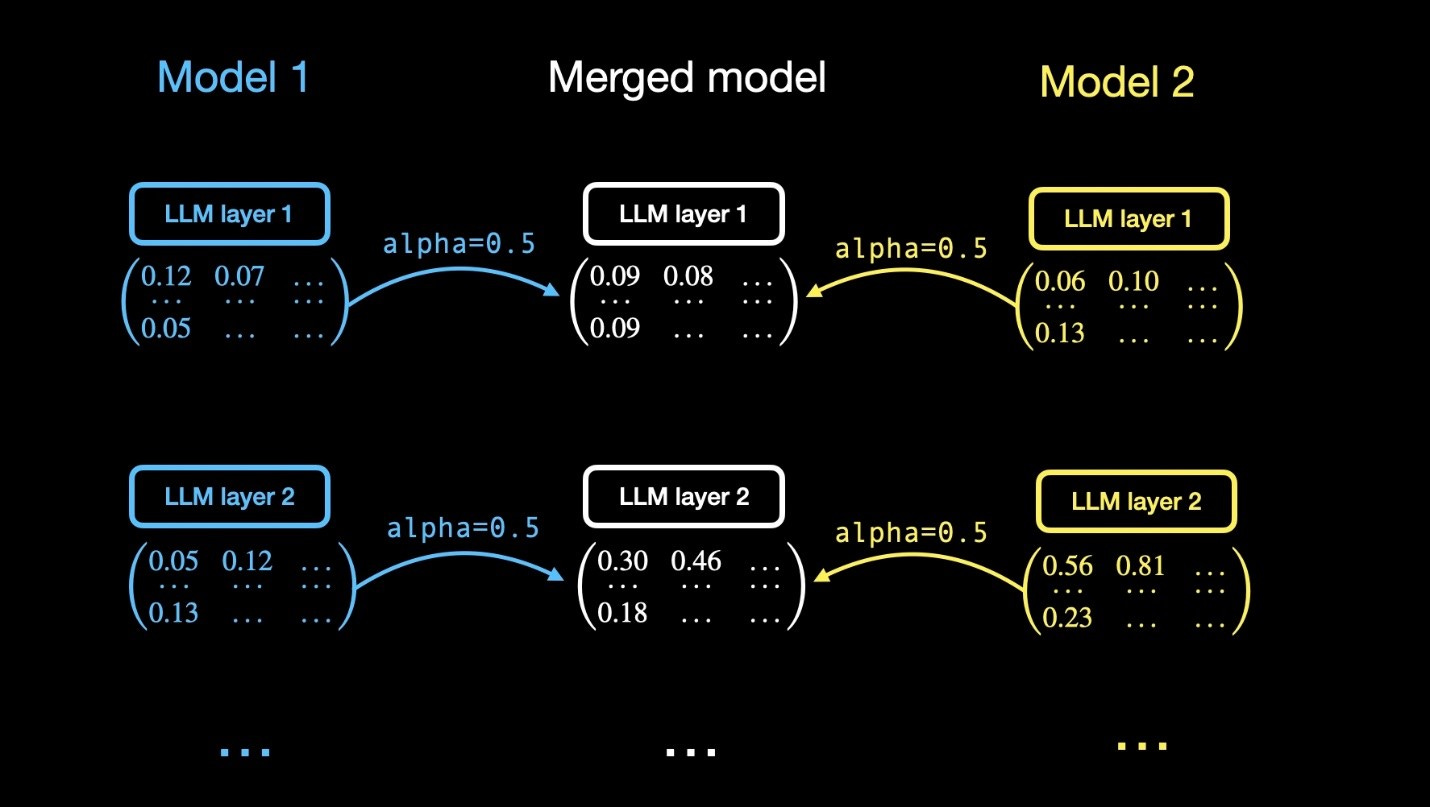
Linear
The linear method employs a weighted average to combine two or more models, with the weight parameter allowing users to precisely control the contribution of each model's characteristics to the final merged model.
Parameters:
· weight - relative (or absolute if normalize=False) weighting of a given tensor
· normalize - if true, the weights of all models contributing to a tensor will be normalized. Default behavior.
SLERP
The Spherical Linear Interpolation (SLERP) method blends the capabilities of LLMs by interpolating between their parameters in a high dimensional space. By treating the models' parameters as points on a hypersphere, SLERP calculates the shortest path between them, ensuring a constant rate of change and maintaining the geometric properties inherent to the models' operational space.
Parameters:
• t - interpolation factor. At t=0 will return base_model, at t=1 will return the other one.
Task Arithmetic
The Task Arithmetic method utilizes "task vectors," created by subtracting the weights of a base model from those of the same model that has been fine-tuned for a specific task. This process effectively captures the directional shifts within the model's weight space, enhancing performance on that task. These task vectors are then linearly combined and reintegrated with the base model's weights. This technique is particularly effective for models fine-tuned from a common ancestor, offering a seamless method for improving model performance. Moreover, it is an invaluable conceptual framework for understanding and implementing complex model-merging strategies.
Parameters: same as Linear
TIES
TIES-merging is currently the most popular model merging method in the LLM community due to its ability to merge more than two models simultaneously.
The TIES-Merging method utilizes the task arithmetic framework to efficiently combine multiple task-specific models into a single multitask model, addressing the challenges of parameter interference and redundancy
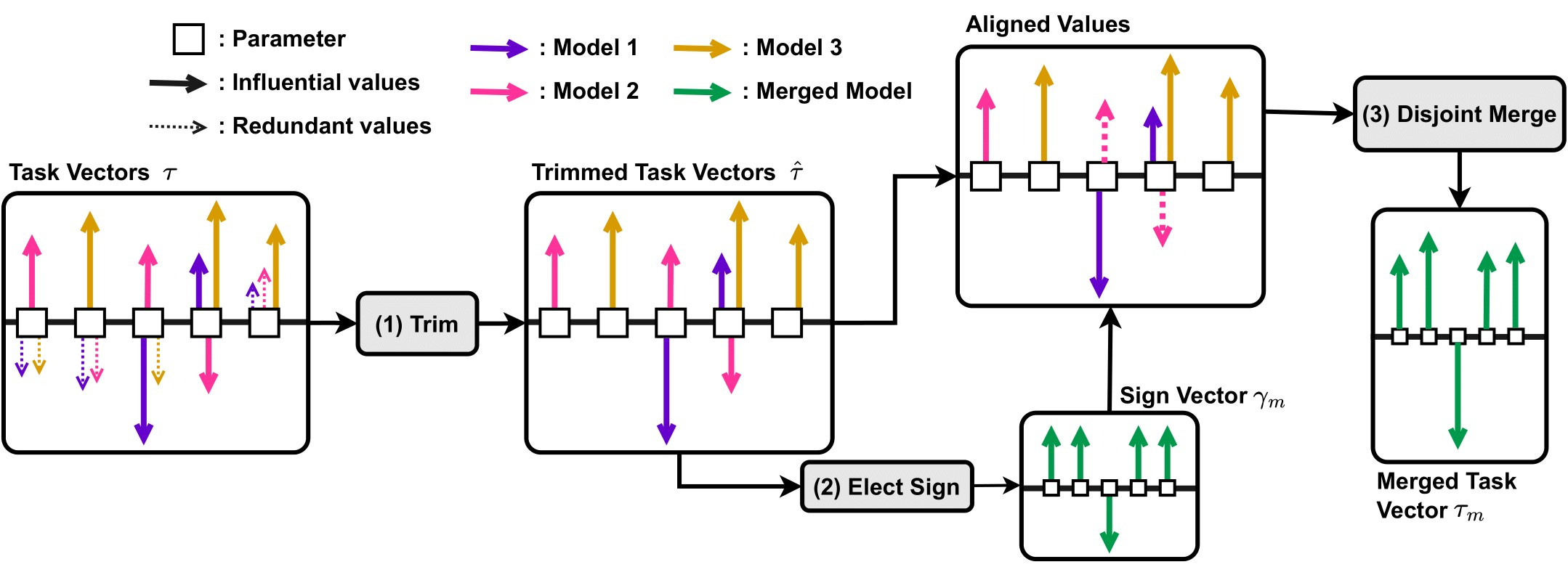
The TIES-Merging method involves three key steps:
Trim: This step reduces redundancy in task-specific models by retaining only the most significant parameters based on a predefined density parameter and setting the rest to zero. It identifies the top-k % most significant changes made during fine-tuning and discards the less impactful ones.
Elect Sign: This step creates a unified sign vector to resolve conflicts from different models suggesting opposing adjustments to the same parameter. This vector represents the most dominant direction of change (positive or negative) across all models based on the cumulative magnitude of the changes.
Disjoint Merge: In the final step, parameter values aligning with the unified sign vector are averaged, excluding zero values. This process ensures that only parameters contributing to the agreed-upon direction of change are merged, enhancing the coherence and performance of the resulting multitask model.
Parameters: same as Linear, plus:
density - fraction of weights in differences from the base model to retain
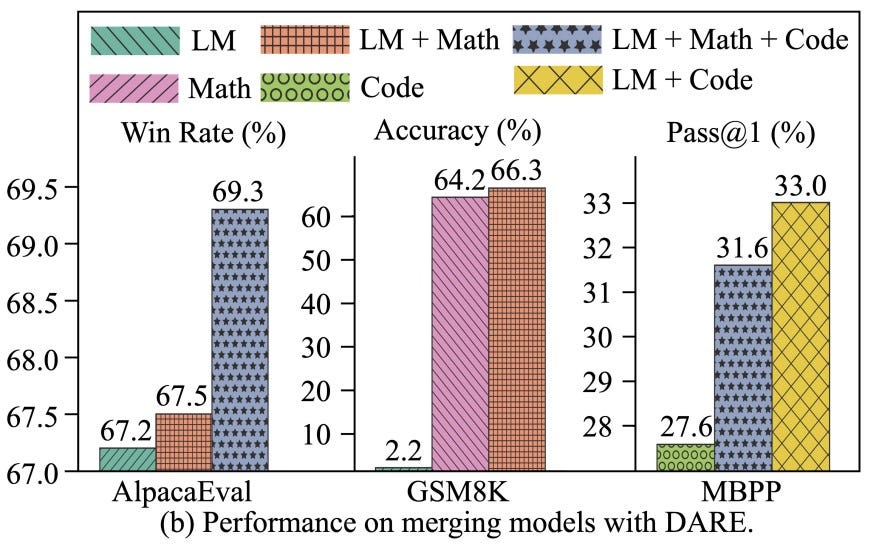
DARE
The DARE (Drop And REscale) method introduces a novel approach to LLM merging, strategically sparsifying delta parameters (differences between fine-tuned and pre-trained parameters) to mitigate interference and enhance performance. Here's a breakdown:
1. Pruning (Sparsification): DARE employs random pruning, resetting fine-tuned weights back to their original values, discarding less impactful changes, and focusing on critical modifications.
2. Rescaling: Following pruning, DARE rescales the remaining weights to maintain output expectations using a calculated scale factor, preserving the performance characteristics of the original models.
3. Merging Variants: DARE offers two options:
With Sign Consensus (dare_ties): Incorporates a sign consensus algorithm, resolving conflicts and unifying parameter adjustment directions for better coherence.
Without Sign Consensus (dare arithmetic): Merges parameters directly for a more straightforward approach, suitable when sign consensus is unnecessary or computationally expensive.
4. Plug-and-Play Capability: DARE works across multiple SFT (Supervised Fine-Tuning) homologous models, enabling their efficient fusion into a single model with diverse capabilities.
5. Performance Enhancement: By strategically eliminating up to 90% or 99% of delta parameters with minimal value ranges, DARE streamlines architecture and demonstrably improves performance. This method successfully merges task-specific LLMs into a unified model with enhanced abilities across various tasks.
Passthrough
passthrough is a no-op that simply passes input tensors through unmodified. Passthrough, this method concatenates layers from different models, enabling the creation of models with a unique number of parameters
Model Stock
Uses some neat geometric properties of fine-tuned models to compute good weights for linear interpolation. Requires at least three models, including a base model.
Parameters:
filter
_wise: if true, weight calculation will be per-row rather than per-tensor. Not recommended.